
شکستن سد تحریمها با معماری توجه پراکنده (DSA)
اهمیت این خبر فراتر از یک آپدیت نرمافزاری ساده است. DeepSeek بار دیگر ثابت کرد که با وجود کنترلهای شدید صادراتی ایالات متحده و عدم دسترسی به پیشرفتهترین تراشههای انویدیا (Nvidia)، قادر به تولید سیستمهای هوش مصنوعی پیشرو (Frontier AI) است.
قلب تپنده این موفقیت، نوآوری معماری جدیدی به نام DeepSeek Sparse Attention (DSA) یا «توجه پراکنده» است. در حالی که مدلهای سنتی با افزایش طول متن ورودی دچار کندی شدید میشوند، معماری DSA با استفاده از یک “نمایهساز صاعقه” (Lightning Indexer) تنها بخشهای مرتبط متن را پردازش میکند. طبق گزارش فنی شرکت، این تکنولوژی هزینه استنتاج (Inference) را برای اسناد طولانی تا ۷۰ درصد کاهش داده است؛ به طوری که پردازش ۱۲۸ هزار توکن (معادل یک کتاب ۳۰۰ صفحهای) اکنون تنها ۰.۷۰ دلار به ازای هر میلیون توکن هزینه دارد (در مقایسه با ۲.۴۰ دلار در مدل قبلی V3.1-Terminus).
مطلب مرتبط: GPT-5.1 منتشر شد؛ خداحافظی با لحن رباتیک و سلام به هوش مصنوعی دوستانهتر
بنچمارکهایی که زنگ خطر را برای سیلیکونولی به صدا درآوردند
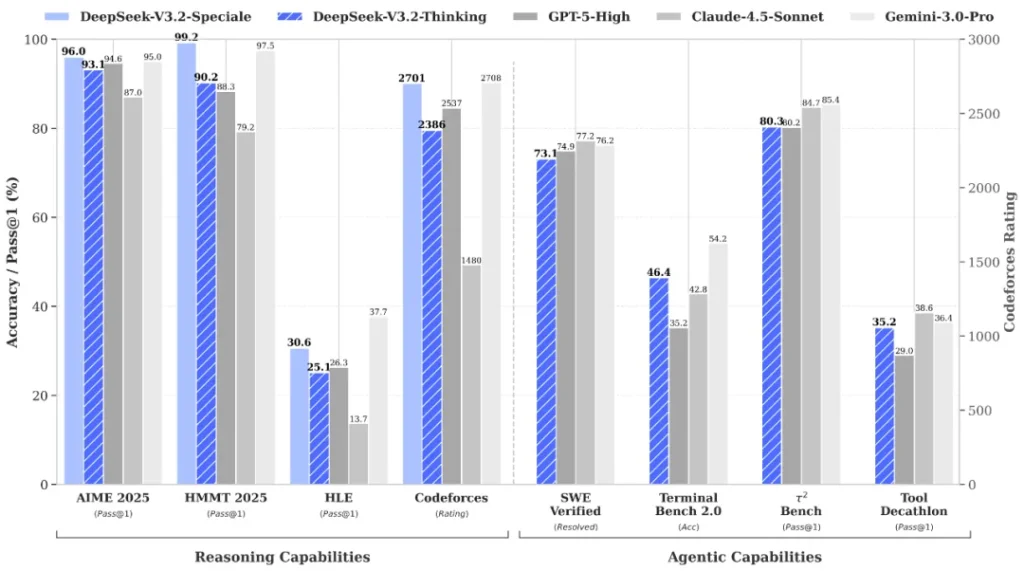
ادعای برابری با GPT-5 صرفاً تبلیغاتی نیست و بر پایه تستهای گسترده استوار است:
- ریاضیات: در رقابت معتبر ریاضی AIME 2025، نسخه Speciale نرخ قبولی ۹۶.۰ درصد را ثبت کرد که بالاتر از GPT-5-High (با ۹۴.۶ درصد) است. در مسابقات ریاضی هاروارد-امآیتی، این مدل با ۹۹.۲ درصد، از ۹۷.۵ درصد Gemini پیشی گرفت.
- کدنویسی: در بنچمارکهای پیچیده کدنویسی (Terminal Bench 2.0)، دیپسیک با امتیاز ۴۶.۴ درصد، فاصله معناداری با GPT-5-High (با ۳۵.۲ درصد) ایجاد کرده است.
- المپیادها: کسب مدال طلا در المپیاد جهانی ریاضی (۳۵ از ۴۲ امتیاز) و قرارگیری در رتبه دهم جهانی در المپیاد انفورماتیک، قدرت استدلال محض این مدل (مدل ۶۸۵ میلیارد پارامتری) را نشان میدهد.
قابلیت «تفکر همزمان با استفاده از ابزارها»؛ جهشی مهم در دنیای هوش مصنوعی
یکی از چالشهای مدلهای زبانی بزرگ (LLM)، قطع شدن رشته افکار هنگام استفاده از ابزارهای خارجی (مثل جستجو در وب یا اجرای کد) بود. DeepSeek با معرفی قابلیت “Thinking in Tool-use” این مشکل را حل کرده است. این مدل میتواند همزمان با استدلال منطقی، کدهای پیچیده را اجرا کرده و فایلها را مدیریت کند؛ قابلیتی که با آموزش روی ۸۵ هزار دستورالعمل پیچیده و شبیهسازی شده به دست آمده است.
تهدید مدل تجاری OpenAI با استراتژی متنباز
برخلاف رویکرد بسته (Closed-Source) شرکتهایی مانند OpenAI و Anthropic که مدلهای پیشرفته خود را به عنوان داراییهای محرمانه حفظ میکنند، DeepSeek این مدلهای ۶۸۵ میلیارد پارامتری را تحت مجوز متنباز MIT منتشر کرده است. این حرکت جسورانه، مدل کسبوکار مبتنی بر فروش API گرانقیمت رقبای آمریکایی را تهدید میکند. چن فنگ، از توسعهدهندگان پروژه، در شبکه اجتماعی X نوشت:
«مردم فکر میکردند DeepSeek یک جرقه یکباره بود، اما ما بسیار بزرگتر بازگشتیم.»
چالشهای پیشرو: از نگرانیهای امنیتی تا تحریمها
با وجود این پیشرفت فنی و توانایی DeepSeek در ارائهی مدلهای متنباز و کمهزینه، این شرکت با دیوارهای بلند رگولاتوری و موانع ژئوپلیتیکی مواجه است. در اروپا، نگرانیهای جدی دربارهی حریم خصوصی دادهها و امنیت ملی مطرح شده است؛ برای مثال، کمیسیون حفاظت از دادههای برلین انتقال دادههای کاربران آلمانی به چین را غیرقانونی دانسته و ایتالیا نیز دستور مسدودسازی این اپلیکیشن را صادر کرده است. علاوه بر این موانع رگولاتوری، تحریمهای صادراتی آمریکا در حوزهی سختافزار همچنان یک چالش کلیدی است. هرچند مدل قبلی DeepSeek (V3) با استفاده از تراشههای قدیمیتر Nvidia H800 آموزش دیده بود، گمانهزنیها حاکی از آن است که مدلهای جدید با استفاده از تراشههای بومی چینی مانند محصولات هواوی (Huawei) و کمبریکن (Cambricon) بهینه شدهاند؛ این موضوع نشان میدهد که تحریمهای سختافزاری نهایتاً نتوانستهاند سرعت پیشرفت هوش مصنوعی چین را متوقف کنند و پکن در حال یافتن راههای جایگزین برای تأمین توان محاسباتی مورد نیاز خود است.
هوش مصنوعی DeepSeek با قابلیتهایی برابر با مدلهای پیشرفته آمریکایی و ارائه رایگان آنها، نشان داد که رقابت هوش مصنوعی بین چین و آمریکا وارد فاز جدیدی شده است.
منبع
DeepSeek just dropped two insanely powerful AI models that rival GPT-5 and they’re totally free